

Separate Chaining:-
The idea is to make each cell of hash table point to a linked list of records that have same hash function value.
The idea is to make each cell of hash table point to a linked list of records that have same hash function value.
Let us consider a simple hash function as “key mod 7” and sequence of keys as 50, 700, 76, 85, 92, 73, 101.
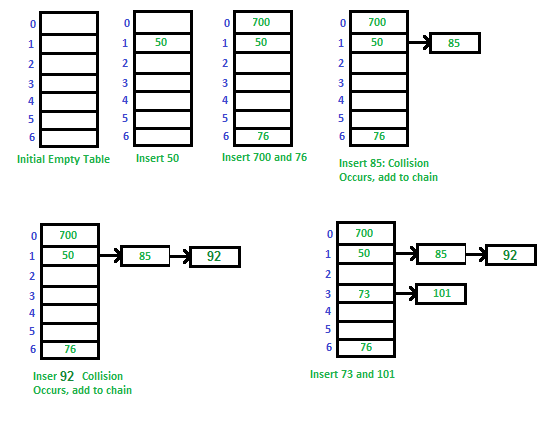
Advantages:
1) Simple to implement.
2) Hash table never fills up, we can always add more elements to chain.
3) Less sensitive to the hash function or load factors.
4) It is mostly used when it is unknown how many and how frequently keys may be inserted or deleted.
1) Simple to implement.
2) Hash table never fills up, we can always add more elements to chain.
3) Less sensitive to the hash function or load factors.
4) It is mostly used when it is unknown how many and how frequently keys may be inserted or deleted.
Disadvantages:
1) Cache performance of chaining is not good as keys are stored using linked list. Open addressing provides better cache performance as everything is stored in same table.
2) Wastage of Space (Some Parts of hash table are never used)
3) If the chain becomes long, then search time can become O(n) in worst case.
4) Uses extra space for links.
1) Cache performance of chaining is not good as keys are stored using linked list. Open addressing provides better cache performance as everything is stored in same table.
2) Wastage of Space (Some Parts of hash table are never used)
3) If the chain becomes long, then search time can become O(n) in worst case.
4) Uses extra space for links.
Performance of Chaining:
Performance of hashing can be evaluated under the assumption that each key is equally likely to be hashed to any slot of table (simple uniform hashing).
m = Number of slots in hash table
n = Number of keys to be inserted in has table
Load factor α = n/m
Expected time to search = O(1 + α)
Expected time to insert/delete = O(1 + α)
Time complexity of search insert and delete is
O(1) if α is O(1)
No comments:
Post a Comment